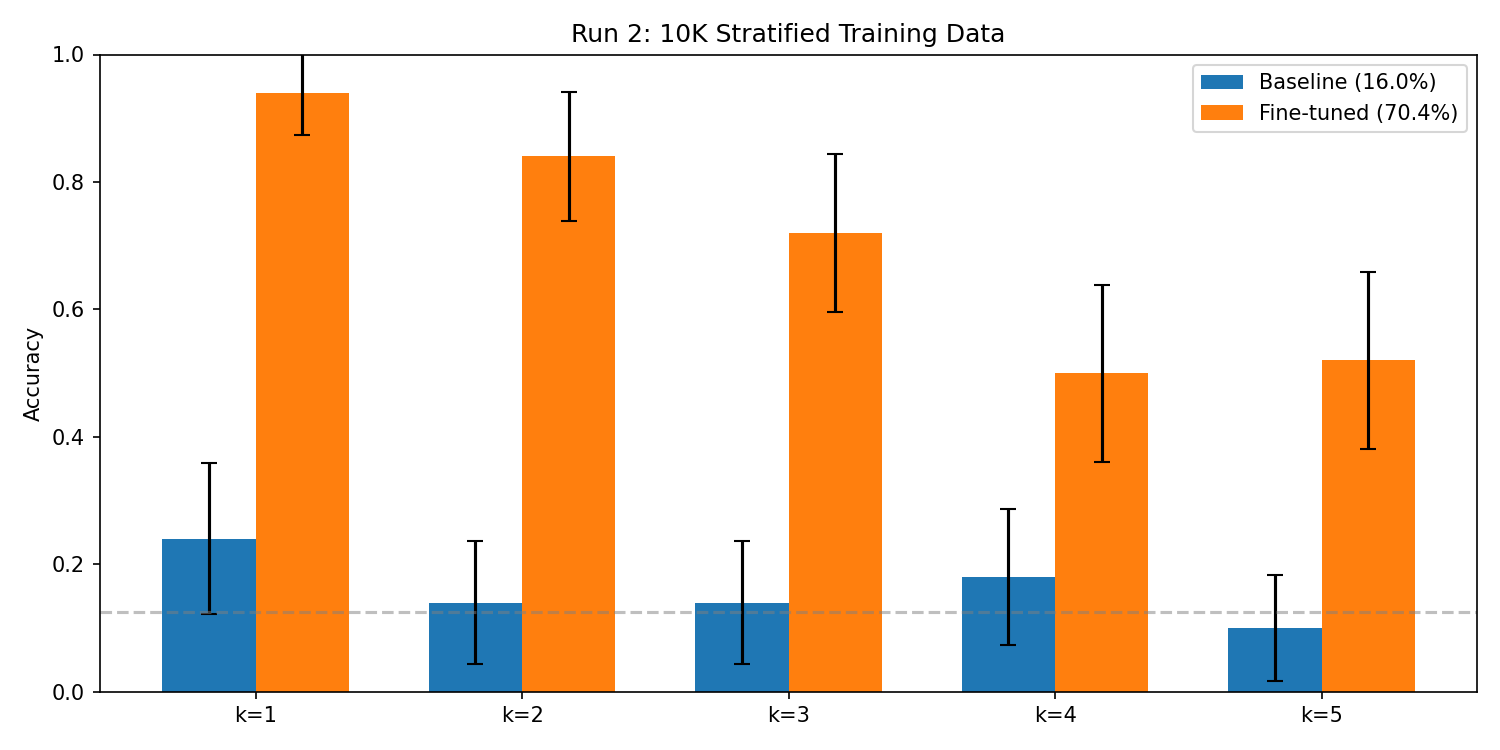
Baseline
16.0%
→
Fine-tuned
70.4%
Change
+54.4%
Accuracy on 250 held-out examples (50 per hop level, k=1-5). Approx. 95% intervals: baseline 11.5%-20.5%, fine-tuned 64.7%-76.1%. Treat the +54.4% overall change as exploratory. Per-hop intervals are wide (n=50 each), so individual hop deltas are directional, not conclusive.
Training Details
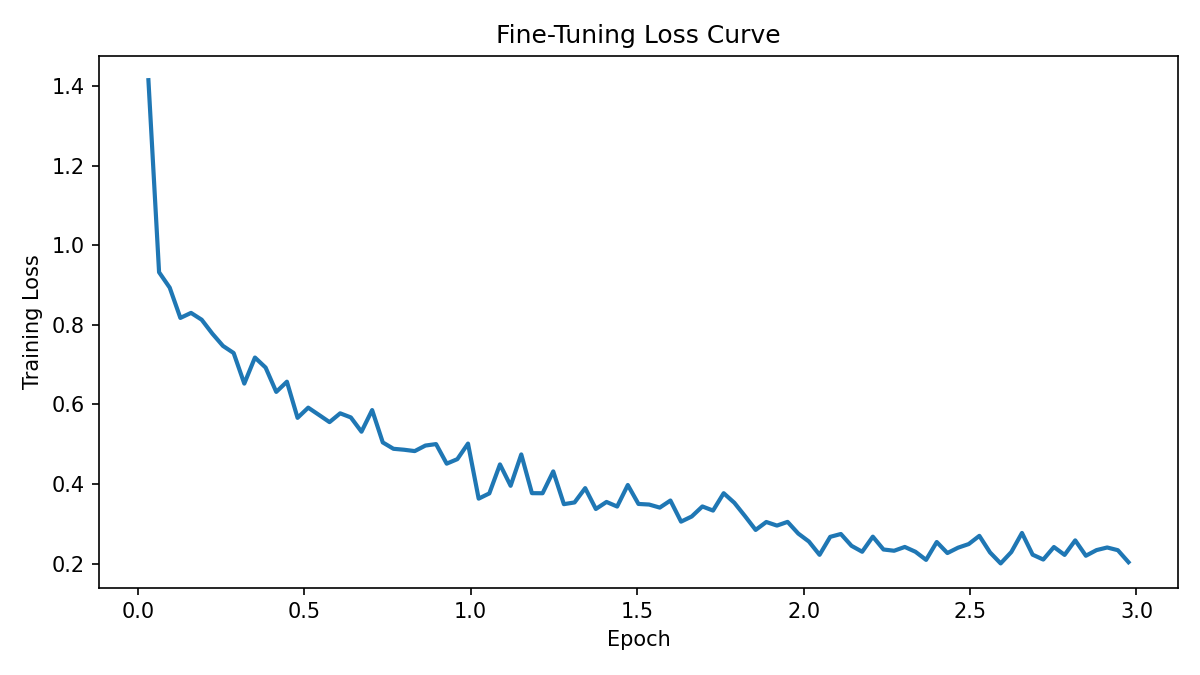
Loss decreased steadily over 3 epochs, so optimization was stable. That stability did not translate into a strong overall evaluation gain.
Training Time
76.8 min
Final Loss
~0.203
Adapter Size
16.0 MB
Model Predictions
Illustrative evaluation examples spanning improvement, regression, stable-correct, and stable-wrong outcomes.